PyBroom Example - Multiple Datasets¶
This notebook is part of pybroom.
This notebook demonstrate using pybroom when fitting a set of curves (curve fitting) using lmfit.Model. We will show that pybroom greatly simplifies comparing, filtering and plotting fit results from multiple datasets.
In [1]:
%matplotlib inline
%config InlineBackend.figure_format='retina' # for hi-dpi displays
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from lmfit import Model
import lmfit
print('lmfit: %s' % lmfit.__version__)
lmfit: 0.9.7
/home/docs/checkouts/readthedocs.org/user_builds/pybroom/envs/latest/lib/python3.5/site-packages/IPython/html.py:14: ShimWarning: The `IPython.html` package has been deprecated since IPython 4.0. You should import from `notebook` instead. `IPython.html.widgets` has moved to `ipywidgets`.
"`IPython.html.widgets` has moved to `ipywidgets`.", ShimWarning)
In [2]:
sns.set_style('whitegrid')
In [3]:
import pybroom as br
Create Noisy Data¶
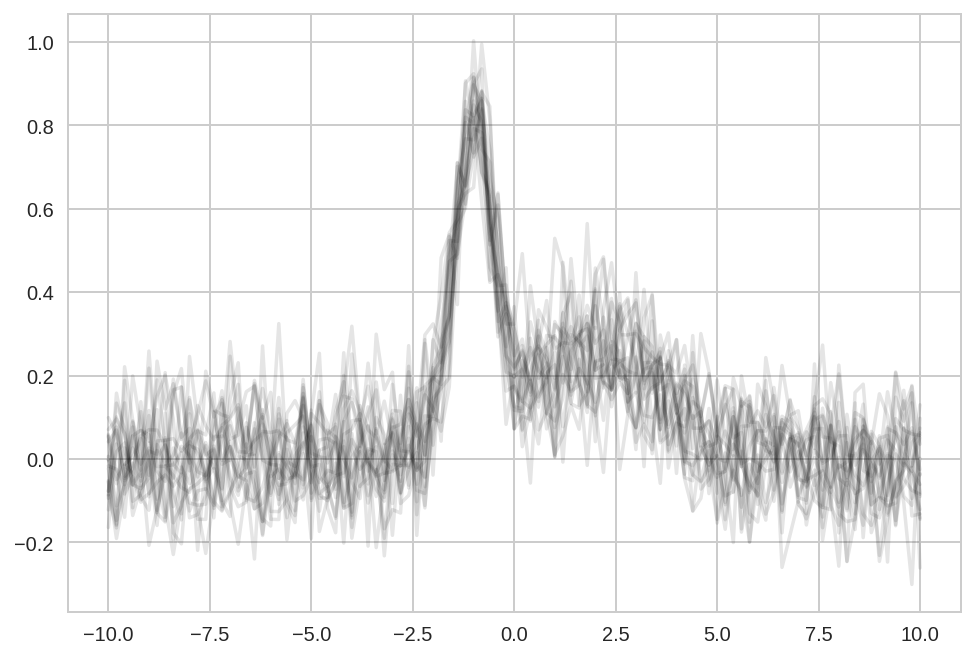
We start simulating N datasets which are identical except for the additive noise.
In [4]:
N = 20
In [5]:
x = np.linspace(-10, 10, 101)
In [6]:
peak1 = lmfit.models.GaussianModel(prefix='p1_')
peak2 = lmfit.models.GaussianModel(prefix='p2_')
model = peak1 + peak2
In [7]:
#params = model.make_params(p1_amplitude=1.5, p2_amplitude=1,
# p1_sigma=1, p2_sigma=1)
In [8]:
Y_data = np.zeros((N, x.size))
Y_data.shape
Out[8]:
(20, 101)
In [9]:
for i in range(Y_data.shape[0]):
Y_data[i] = model.eval(x=x, p1_center=-1, p2_center=2,
p1_sigma=0.5, p2_sigma=1.5,
p1_height=1, p2_height=0.5)
Y_data += np.random.randn(*Y_data.shape)/10
In [10]:
plt.plot(x, Y_data.T, '-k', alpha=0.1);
Model Fitting¶
Single-peak model¶
Define and fit a single Gaussian model to the \(N\) datasets:
In [11]:
model1 = lmfit.models.GaussianModel()
In [12]:
Results1 = [model1.fit(y, x=x) for y in Y_data]
Two-peaks model¶
Here, instead, we use a more appropriate Gaussian mixture model.
To fit the noisy data, the residuals (the difference between model and data) is minimized in the least-squares sense.
In [13]:
params = model.make_params(p1_center=0, p2_center=3,
p1_sigma=0.5, p2_sigma=1,
p1_amplitude=1, p2_amplitude=2)
In [14]:
Results = [model.fit(y, x=x, params=params) for y in Y_data]
Fit results from an lmfit Model can be inspected with with
fit_report or params.pretty_print():
In [15]:
#print(Results[0].fit_report())
#Results[0].params.pretty_print()
This is good for peeking at the results. However, extracting these data from lmfit objects is quite a chore and requires good knowledge of lmfit objects structure.
pybroom helps in this task: it extracts data from fit results and returns familiar pandas DataFrame (in tidy format). Thanks to the tidy format these data can be much more easily manipulated, filtered and plotted.
Glance¶
A summary of the two-peaks model fit:
In [16]:
dg = br.glance(Results, var_names='dataset')
dg.drop('model', 1).drop('message', 1).head()
Out[16]:
| method | num_params | num_data_points | chisqr | redchi | AIC | BIC | num_func_eval | success | dataset | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | leastsq | 6 | 101 | 1.145367 | 0.012056 | -440.418975 | -424.728252 | 80 | True | 0 |
| 1 | leastsq | 6 | 101 | 0.880633 | 0.009270 | -466.965754 | -451.275031 | 59 | True | 1 |
| 2 | leastsq | 6 | 101 | 0.752634 | 0.007922 | -482.828918 | -467.138195 | 95 | True | 2 |
| 3 | leastsq | 6 | 101 | 0.746746 | 0.007860 | -483.622251 | -467.931527 | 80 | True | 3 |
| 4 | leastsq | 6 | 101 | 1.022689 | 0.010765 | -451.861188 | -436.170465 | 101 | True | 4 |
A summary of the one-peak model fit:
In [17]:
dg1 = br.glance(Results1, var_names='dataset')
dg1.drop('model', 1).drop('message', 1).head()
Out[17]:
| method | num_params | num_data_points | chisqr | redchi | AIC | BIC | num_func_eval | success | dataset | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | leastsq | 3 | 101 | 1.850787 | 0.018886 | -397.950482 | -390.105121 | 115 | True | 0 |
| 1 | leastsq | 3 | 101 | 1.303274 | 0.013299 | -433.374332 | -425.528970 | 63 | True | 1 |
| 2 | leastsq | 3 | 101 | 1.724410 | 0.017596 | -405.093812 | -397.248451 | 43 | True | 2 |
| 3 | leastsq | 3 | 101 | 2.043674 | 0.020854 | -387.937525 | -380.092163 | 105 | True | 3 |
| 4 | leastsq | 3 | 101 | 2.376938 | 0.024254 | -372.680057 | -364.834695 | 107 | True | 4 |
Tidy¶
Tidy fit results for all the parameters:
In [18]:
dt = br.tidy(Results, var_names='dataset')
Let’s see the results for a single dataset:
In [19]:
dt.query('dataset == 0')
Out[19]:
| name | value | min | max | vary | expr | stderr | init_value | dataset | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | p1_amplitude | 0.926646 | -inf | inf | True | None | 0.190639 | 1.0 | 0 |
| 1 | p1_center | -1.087737 | -inf | inf | True | None | 0.058759 | 0.0 | 0 |
| 2 | p1_fwhm | 1.285132 | -inf | inf | False | 2.3548200*p1_sigma | 0.189530 | NaN | 0 |
| 3 | p1_height | 0.677383 | -inf | inf | False | 0.3989423*p1_amplitude/max(1.e-15, p1_sigma) | 0.082226 | NaN | 0 |
| 4 | p1_sigma | 0.545745 | 0.000000 | inf | True | None | 0.080486 | 0.5 | 0 |
| 5 | p2_amplitude | 1.174310 | -inf | inf | True | None | 0.281646 | 2.0 | 0 |
| 6 | p2_center | 1.603433 | -inf | inf | True | None | 0.589793 | 3.0 | 0 |
| 7 | p2_fwhm | 4.895003 | -inf | inf | False | 2.3548200*p2_sigma | 1.197038 | NaN | 0 |
| 8 | p2_height | 0.225371 | -inf | inf | False | 0.3989423*p2_amplitude/max(1.e-15, p2_sigma) | 0.032352 | NaN | 0 |
| 9 | p2_sigma | 2.078716 | 0.000000 | inf | True | None | 0.508335 | 1.0 | 0 |
or for a single parameter across datasets:
In [20]:
dt.query('name == "p1_center"').head()
Out[20]:
| name | value | min | max | vary | expr | stderr | init_value | dataset | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | p1_center | -1.087737 | -inf | inf | True | None | 0.058759 | 0.0 | 0 |
| 11 | p1_center | -0.985144 | -inf | inf | True | None | 0.050625 | 0.0 | 1 |
| 21 | p1_center | -0.987962 | -inf | inf | True | None | 0.037483 | 0.0 | 2 |
| 31 | p1_center | -1.032991 | -inf | inf | True | None | 0.040458 | 0.0 | 3 |
| 41 | p1_center | -0.990100 | -inf | inf | True | None | 0.044825 | 0.0 | 4 |
In [21]:
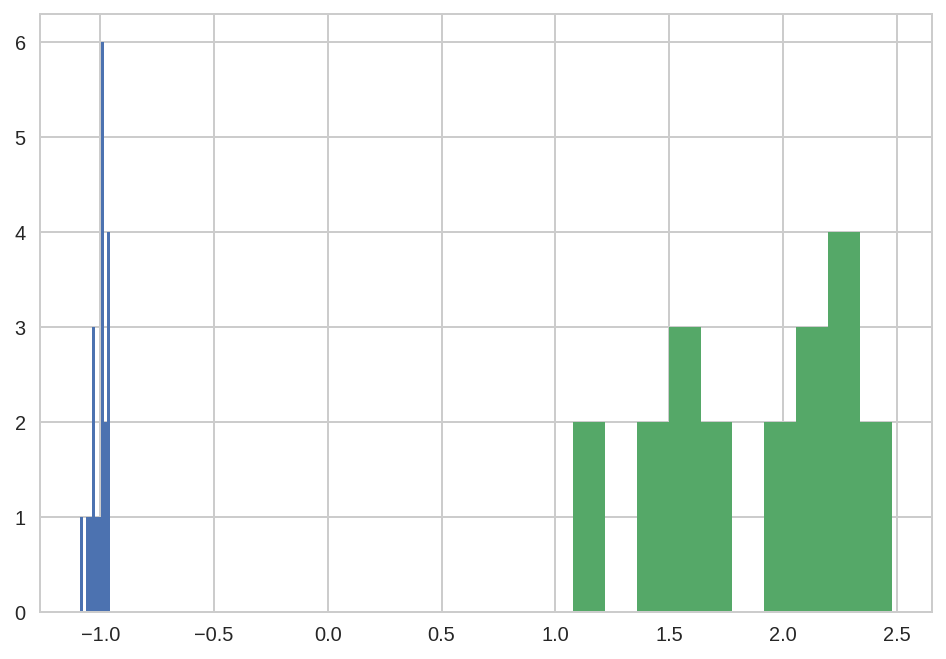
dt.query('name == "p1_center"')['value'].std()
Out[21]:
0.035626705561751418
In [22]:
dt.query('name == "p2_center"')['value'].std()
Out[22]:
0.4123156933193024
Note that there is a much larger error in fitting p2_center than
p1_center.
In [23]:
dt.query('name == "p1_center"')['value'].hist()
dt.query('name == "p2_center"')['value'].hist(ax=plt.gca());
Augment¶
Tidy dataframe with data function of the independent variable (‘x’). Columns include the data being fitted, best fit, best fit components, residuals, etc.
In [24]:
da = br.augment(Results, var_names='dataset')
In [25]:
da1 = br.augment(Results1, var_names='dataset')
In [26]:
r = Results[0]
Let’s see the results for a single dataset:
In [27]:
da.query('dataset == 0').head()
Out[27]:
| x | data | best_fit | residual | Model(gaussian, prefix='p1_') | Model(gaussian, prefix='p2_') | dataset | |
|---|---|---|---|---|---|---|---|
| 0 | -10.0 | -0.121893 | 3.862094e-08 | 0.121893 | 8.342024e-59 | 3.862094e-08 | 0 |
| 1 | -9.8 | 0.035362 | 6.577435e-08 | -0.035362 | 3.098875e-56 | 6.577435e-08 | 0 |
| 2 | -9.6 | 0.134672 | 1.109865e-07 | -0.134672 | 1.006492e-53 | 1.109865e-07 | 0 |
| 3 | -9.4 | -0.101508 | 1.855510e-07 | 0.101508 | 2.858187e-51 | 1.855510e-07 | 0 |
| 4 | -9.2 | -0.086389 | 3.073522e-07 | 0.086390 | 7.096505e-49 | 3.073522e-07 | 0 |
Plotting a single dataset is simplified compared to a manual plot:
In [28]:
da0 = da.query('dataset == 0')
In [29]:
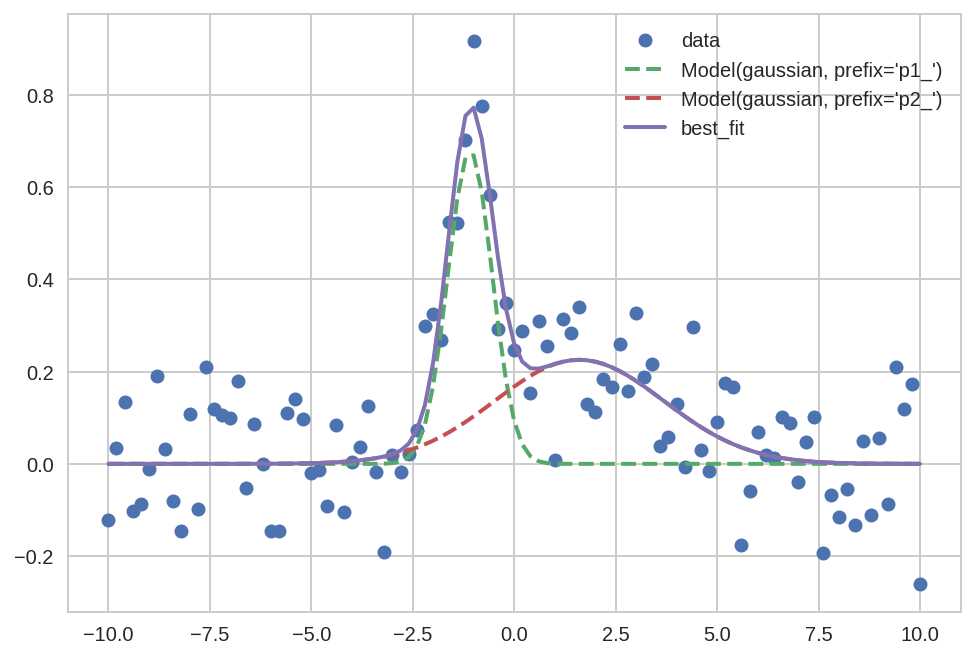
plt.plot('x', 'data', data=da0, marker='o', ls='None')
plt.plot('x', "Model(gaussian, prefix='p1_')", data=da0, lw=2, ls='--')
plt.plot('x', "Model(gaussian, prefix='p2_')", data=da0, lw=2, ls='--')
plt.plot('x', 'best_fit', data=da0, lw=2);
plt.legend()
Out[29]:
<matplotlib.legend.Legend at 0x7fad6f261128>
But keep in mind that, for a single dataset, we could use the lmfit method as well (which is even simpler):
In [30]:
Results[0].plot_fit();
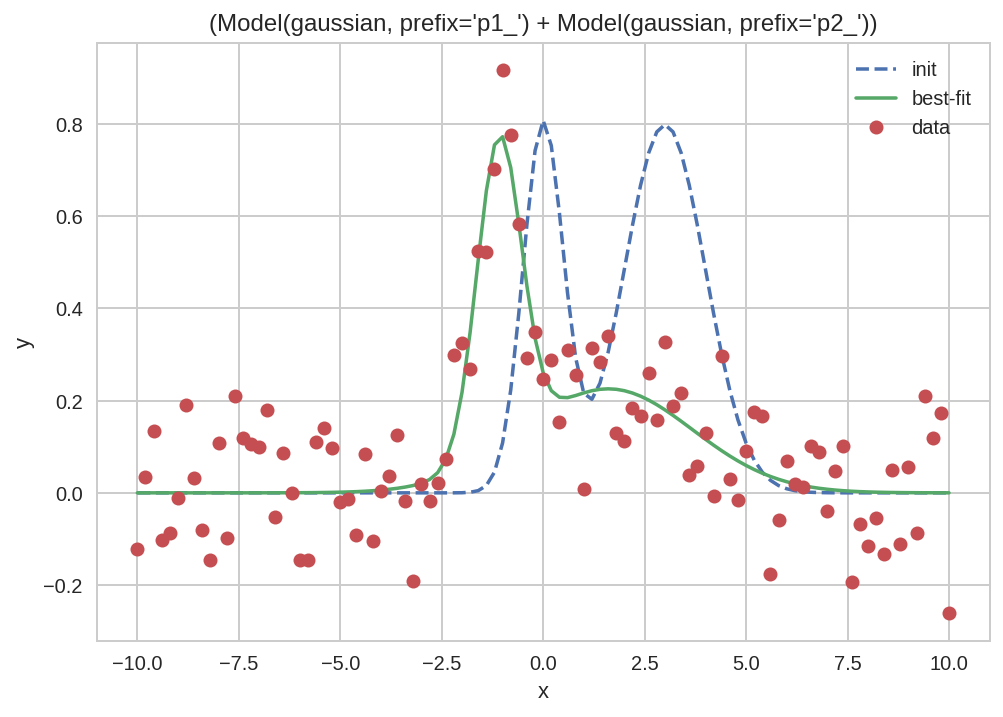
However, things become much more interesting when we want to plot multiple datasets or models as in the next section.
Comparison of different datasets¶
In [31]:
grid = sns.FacetGrid(da.query('dataset < 6'), col="dataset", hue="dataset", col_wrap=3)
grid.map(plt.plot, 'x', 'data', marker='o', ls='None', ms=3, color='k')
grid.map(plt.plot, 'x', "Model(gaussian, prefix='p1_')", ls='--')
grid.map(plt.plot, 'x', "Model(gaussian, prefix='p2_')", ls='--')
grid.map(plt.plot, "x", "best_fit");
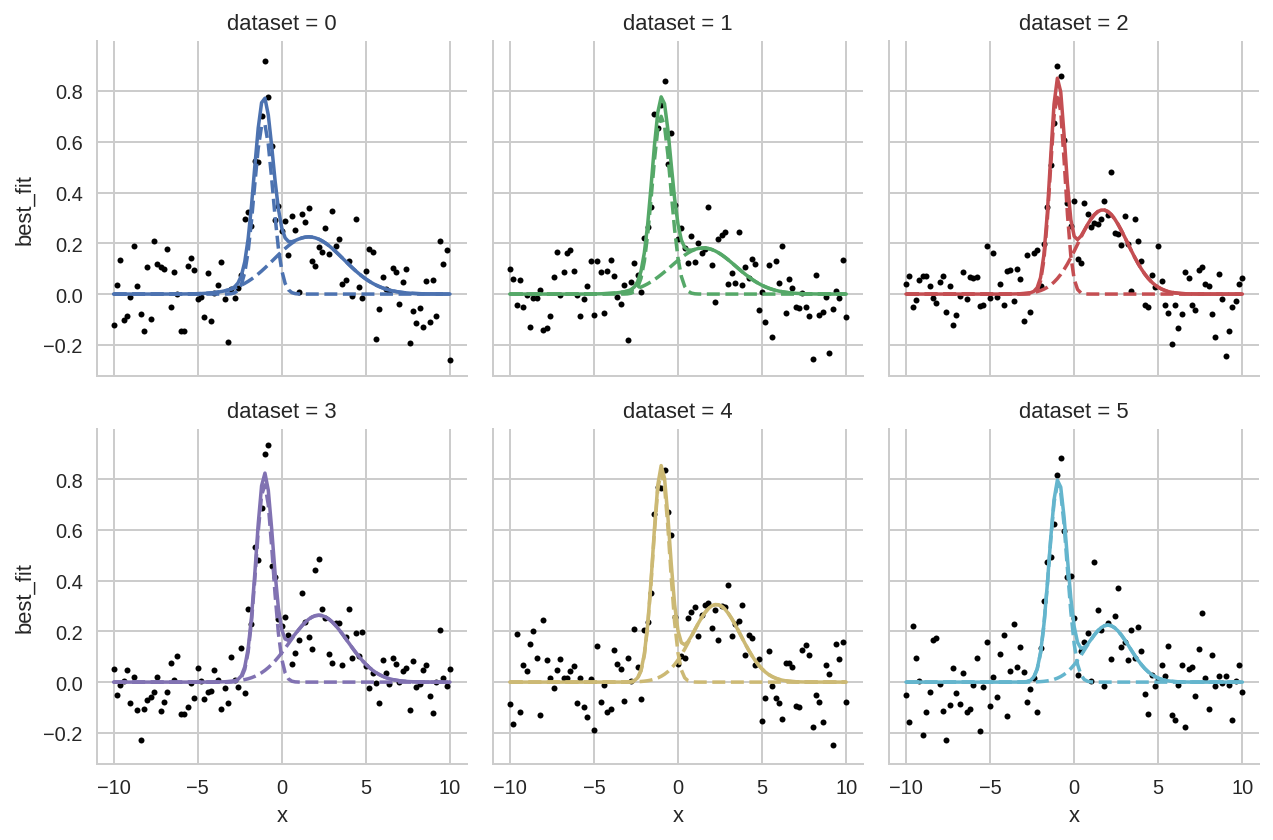
Comparison of one- or two-peaks models¶
Here we plot a comparison of the two fitted models (one or two peaks) for different datasets.
First we create a single tidy DataFrame with data from the two models:
In [32]:
da['model'] = 'twopeaks'
da1['model'] = 'onepeak'
da_tot = pd.concat([da, da1], ignore_index=True)
Then we perfom a facet plot with seaborn:
In [33]:
grid = sns.FacetGrid(da_tot.query('dataset < 6'), col="dataset", hue="model", col_wrap=3)
grid.map(plt.plot, 'x', 'data', marker='o', ls='None', ms=3, color='k')
grid.map(plt.plot, "x", "best_fit")
grid.add_legend();
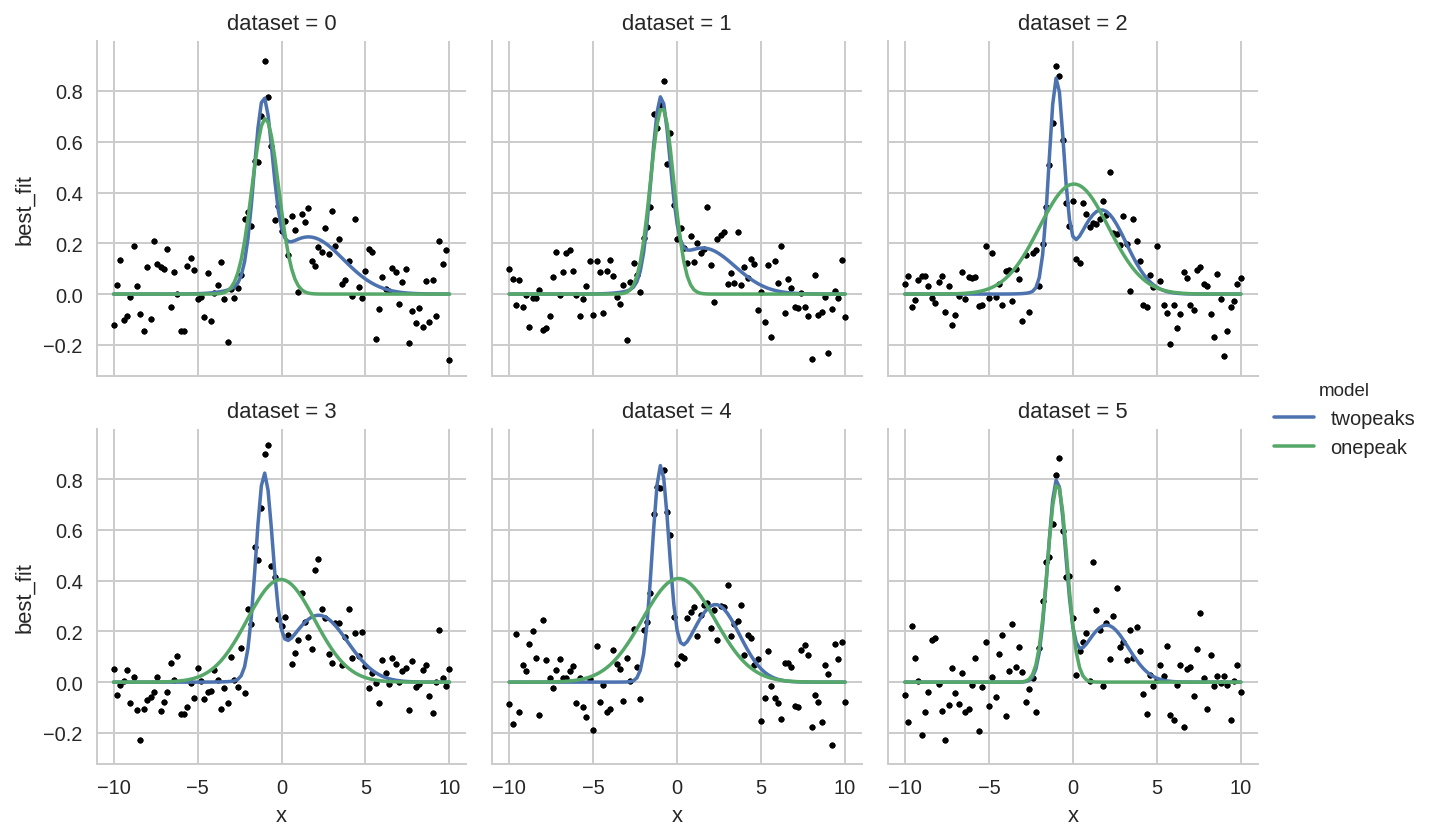
Note that the “tidy” organization of data allows plot libraries such as seaborn to automatically infer most information to create complex plots with simple commands. Without tidy data, instead, a manual creation of such plots becomes a daunting task.